
Auditing Data Provenance in Machine Learning Models
In this paper, the authors design and evaluate a technology that can help users audit machine learning models to determine if their data was used to train these models.
-Firstly, we introduce the problem and some definitions. and then review challenges and goels. Then we explain the propose method and finally discuss the results.
-Chatbots are used in many applications, for example, automated agents, smart home assistants, and interactive characters in online games. Therefore, it is crucial to ensure they do not behave in undesired manners and provide offensive or toxic responses to users.
Here we talk about Model Auditing; their purpose is a technique that helps users check if their data was used to train a machine learning model.
-This paper is “Auditing Data Provenance in Text-Generation Models” that is published in the Proceedings of the 2019 ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. The authors develop a new model auditing technique that helps users audit machine learning models to determine if their data was used to train these models. They focus on auditing models that generate natural-language text, including word prediction and dialogue generation. They assume that the auditor has only black-box access to the model and can query it only on a limited number of inputs. They also work with text-generation models that are trained on the data of thousands of users and are well-generalized. They measure how many queries are needed to determine if the user’s data was used.

-The goal is designing and evaluating a technology that can help users audit machine learning models to determine if their data was used to train these models.

-They focus on auditing models that generate natural-language text, including word prediction and dialogue generation. Next-word prediction is used in many natural-language applications, including predictive virtual keyboards and query auto-completion. Neural machine translation (NMT) models based on RNNs reach near-human performance on many language pairs. Dialogue generation aims to generate replies in a conversation. It is a common component of chatbots and question-answering services.
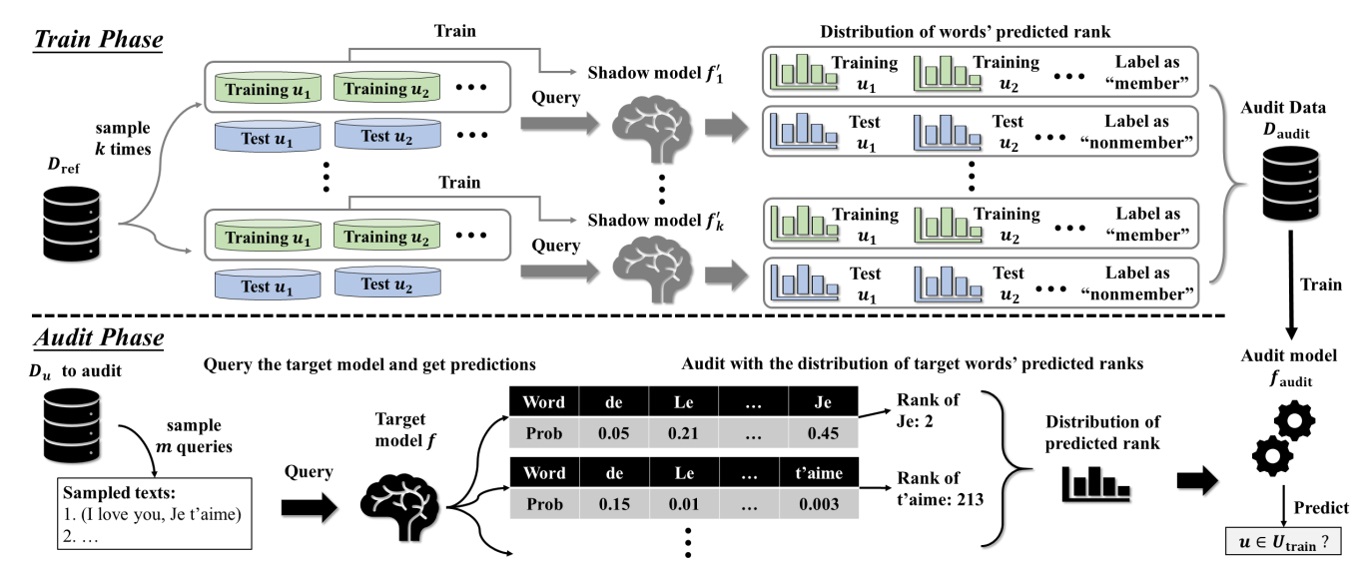
-In their approach, the auditor needs an auxiliary dataset to train shadow models that perform the same task as the target model. They query the shadow models with the dataset for each user and label the resulting outputs as “member” if the user was part of the shadow’s training data and “non-member” otherwise. They assume that the auditor knows the learning algorithm used to create the model but may or may not know the training hyper-parameters. The auditor’s goal is to learn to distinguish the target model’s outputs on sequences it trained on and sequences it did not see during training. The next step is to train a binary membership classifier with these labelled predictions. They build a binary membership classifier faudit that takes as input a list of predictions obtained by querying the target model with a subset of the user’s dataset and outputs a decision on u ∈ Utrain.
-The used datasets are Reddit comments dataset (Reddit), speaker annotated TED talks dataset (SATED), and Cornell movie dialogues corpus (Dialogs). As the cross-domain datasets for word prediction, they use the Wikitext-103 corpus. For translation, they use the English-French pair in the Europarl dataset, a parallel language corpus extracted from the proceedings of the European Parliament. They use the Ubuntu dialogues dataset for dialogue generation, which contains two-person technical support chat logs.
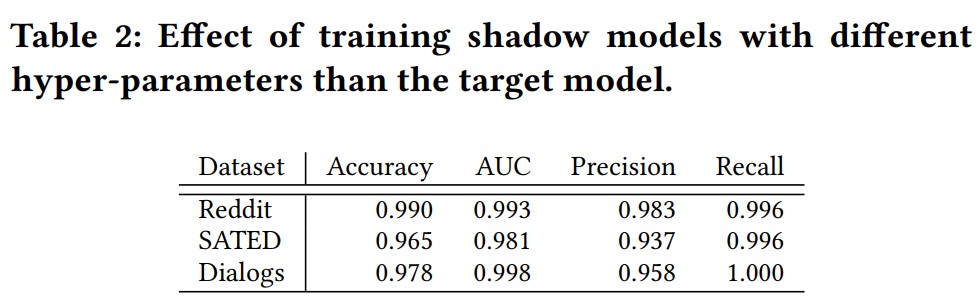
-They train 10 shadow models for each task with different training configurations. This Table shows the results. Auditing scores are still above 0.95 on nearly all metrics for all tasks and models.
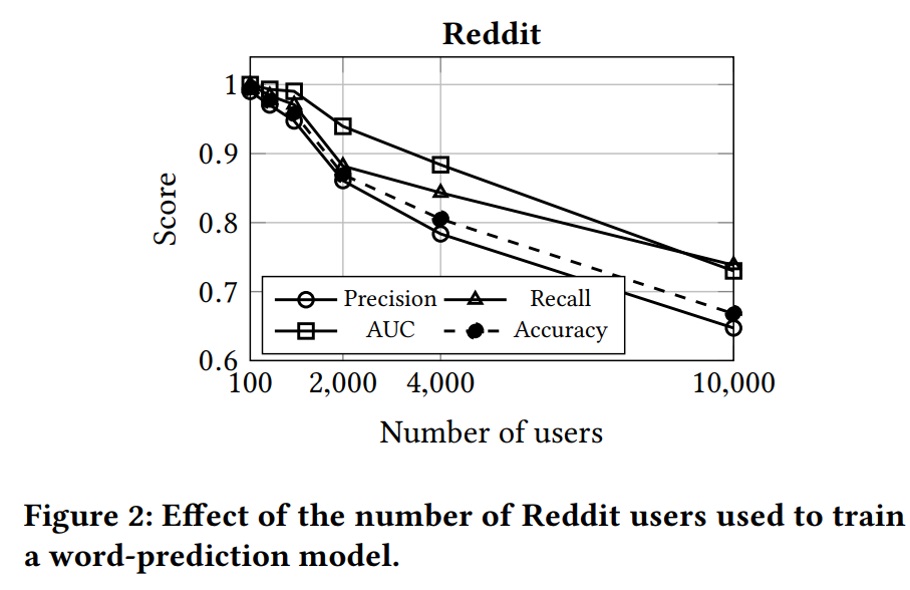
-They use one-half of the shadow users to train shadow models and the other half to collect the shadow models’ outputs on the non-members. They train ten shadow models for all tasks and use a linear SVM as the audit classifier. Their audit model achieves the perfect score (i.e., 1) on accuracy, precision and recall metrics for all datasets and models when there is no restriction on the target models. Results demonstrate that knowledge of the target model’s hyper-parameters is not essential for successful auditing. The number of users in the training dataset affects the auditor’s ability to infer the presence of a single user so that, changing from 100 to 10000 users, accuracy changes from 99% to 67%.
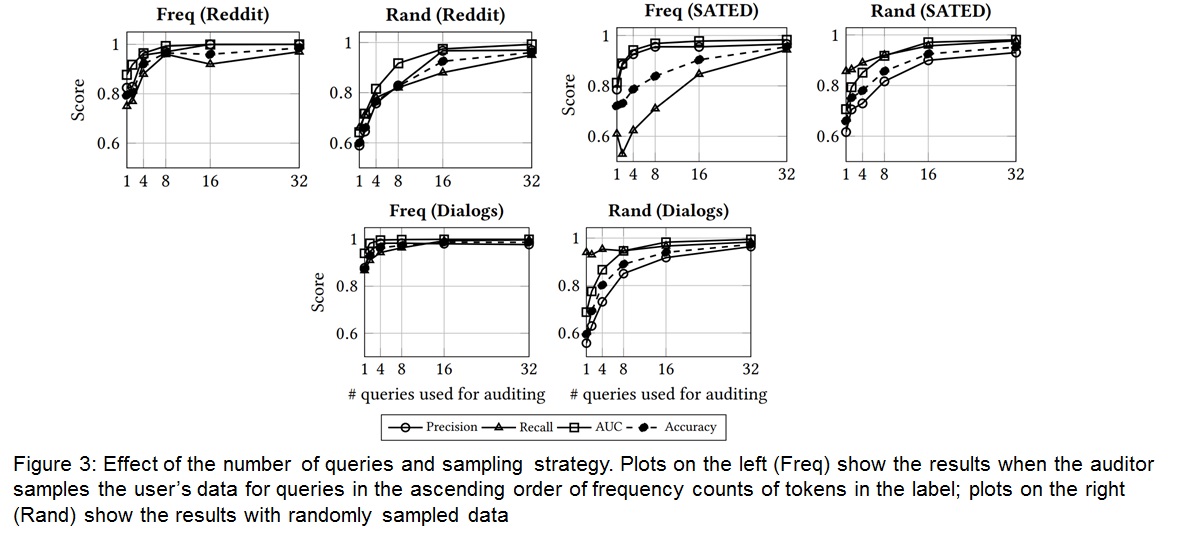
-To measure the performance of auditing when the auditor is restricted to only a few queries, They vary the number of audit queries between 1, 2, 4, 8, 16, and 32 word sequences. This Figure shows the results. With 32 queries, audit performance exceeds 0.9 on all metrics for all datasets. If query selection is random, audit performance is low, with fewer than 8 queries. If the auditor queries the target with the user’s word sequences whose summary word-frequency counts are the lowest, even with a single query, the auditor can accurately determine if the user’s data was used to train the model
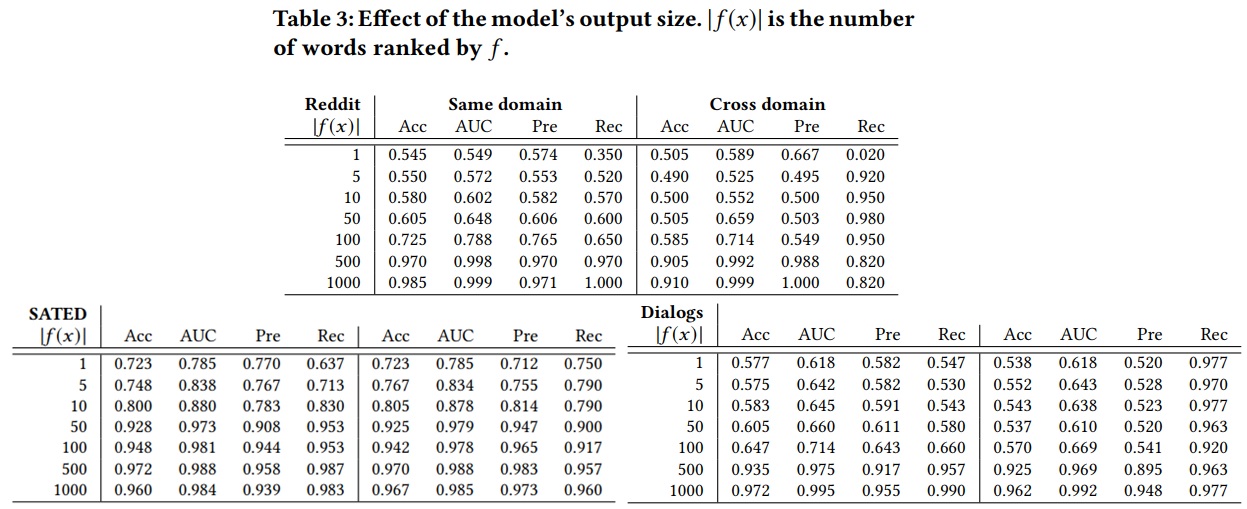
-They constrain the model’s output to the top-ranked 1, 5, 50, 500, and 1000 words, while the other hyper-parameters remain fixed. The result shows that in most cases, the auditor’s performance is close to random guessing when the model’s outputs are limited to the top 50 or fewer words, increasing to above 0.9 when the output size is the top 500 words. For the translation task, audit performance is much higher than random guessing, even if the model outputs just one top-ranked word. This demonstrates that machine learning-based translation models are more prone than word-prediction models to memorize training sequences in their inner units.
They show that sequences that include relatively rare words are more effective for auditing than word sequences randomly selected from the user’s data. They discuss text generation applications such as next-word prediction, neural machine translation, and dialogue generation.
In general, this paper can help detect unauthorized uses of sensitive personal data and ensure compliance with GDPR and other data-protection policies and regulations.
–> Link to the Paper <–