
High-Resolution Image Synthesis with Latent Diffusion Models
In this paper, the authors have presented latent diffusion models, to improve efficiency of de-noising diffusion models without degrading their quality. Diffusion Models are generative models, meaning that they are used to generate data similar to the data on which they are trained. Fundamentally, Diffusion Models work by destroying training data through the successive addition of Gaussian noise, and then learning to recover the data by reversing this noising process. After training, we can use the Diffusion Model to generate data by simply passing randomly sampled noise through the learned denoising process.

Although Diffusion Models are computationally more expensive than other deep network architectures, however, they perform much better in certain applications. For example, recent applications to text and image synthesis tasks, Diffusion Models have out-performed over other architectures.
The key concept in Diffusion Modelling is that if we could build a learning model which can learn the systematic decay of information due to noise, then it should be possible to reverse the process and therefore, recover the information back from the noise. This concept is similar to VAEs in the way that it tries to optimize an objective function by first projecting the data onto the latent space and then recovering it back to the initial state. However, instead of learning the data distribution, the system aims to model a series of noise distributions in a Markov Chain and “decodes” the data by undoing/denoising the data in a hierarchical fashion.
Diffusion models:
• Pros: Tractability and flexibility are two conflicting objectives in generative modeling. Tractable models can be analytically evaluated and cheaply fit data (e.g. via a Gaussian or Laplace), but they cannot easily describe the structure in rich datasets. Flexible models can fit arbitrary structures in data, but evaluating, training, or sampling from these models is usually expensive. Diffusion models are both analytically tractable and flexible
• Cons: Diffusion models rely on a long Markov chain of diffusion steps to generate samples, so it can be quite expensive in terms of time and compute. New methods have been proposed to make the process much faster, but the sampling is still slower than GAN.

Abstract: By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism to control the image generation process without retraining. However, since these models typically operate directly in pixel space, optimization of powerful DMs often consumes hundreds of GPU days and inference is expensive due to sequential evaluations. To enable DM training on limited computational resources while retaining their quality and flexibility, we apply them in the latent space of powerful pretrained autoencoders. In contrast to previous work, training diffusion models on such a representation allows for the first time to reach a near-optimal point between complexity reduction and detail preservation, greatly boosting visual fidelity. By introducing cross-attention layers into the model architecture, we turn diffusion models into powerful and flexible generators for general conditioning inputs such as text or bounding boxes and high-resolution synthesis becomes possible in a convolutional manner. Our latent diffusion models (LDMs) achieve a new state of the art for image inpainting and highly competitive performance on various tasks, including unconditional image generation, semantic scene synthesis, and super-resolution, while significantly reducing computational requirements compared to pixel-based DMs.
Latent diffusion model (LDM; Rombach & Blattmann, et al. 2022) runs the diffusion process in the latent space instead of pixel space, making training cost lower and inference speed faster. It is motivated by the observation that most bits of an image contribute to perceptual details and the semantic and conceptual composition still remains after aggressive compression. LDM loosely decomposes the perceptual compression and semantic compression with generative modeling learning by first trimming off pixel-level redundancy with autoencoder and then manipulate/generate semantic concepts with diffusion process on learned latent.

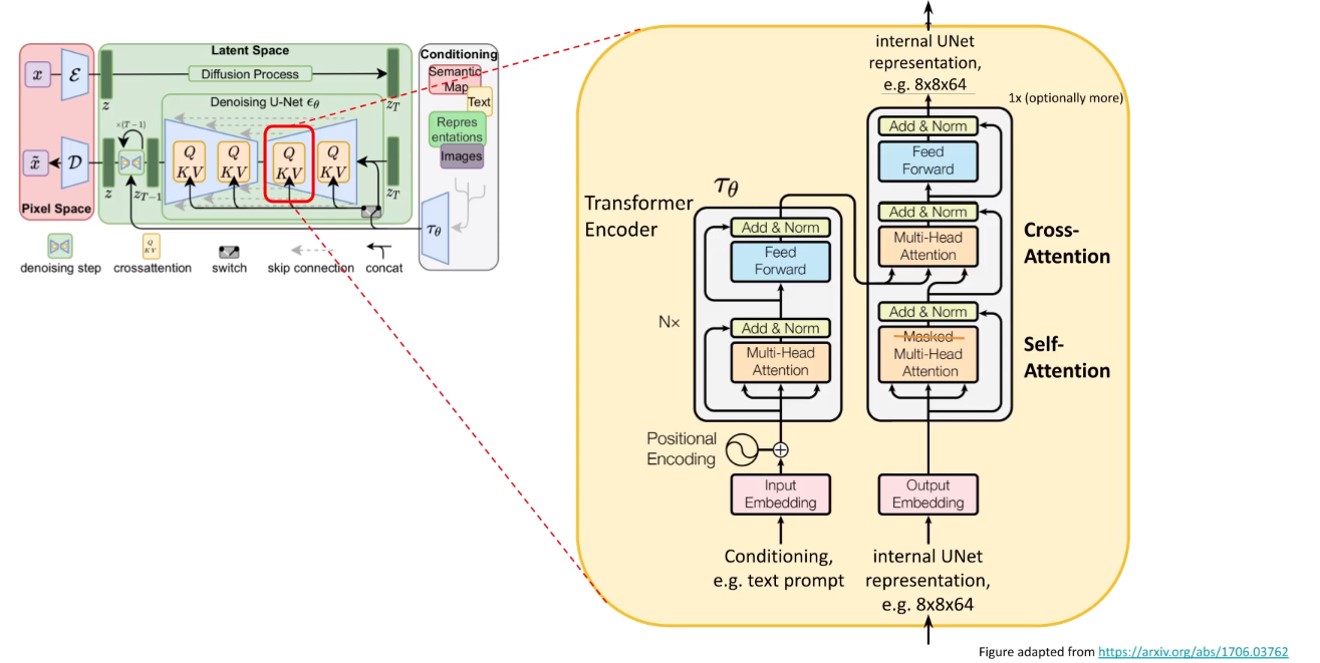
The diffusion and denoising processes happen on the latent vector z. The denoising model is a time-conditioned U-Net, augmented with the cross-attention mechanism to handle flexible conditioning information for image generation (e.g. class labels, semantic maps, blurred variants of an image). The design is equivalent to fuse representation of different modality into the model with cross-attention mechanism. Each type of conditioning information is paired with a domain-specific encoder τθ to project the conditioning input y to an intermediate representation that can be mapped into cross-attention components.
Diffusion models rely on a long Markov chain of diffusion steps to generate samples, so it can be quite expensive in terms of time and compute. New methods have been proposed to make the process much faster, but the sampling is still slower than GAN.
Contributions:
1-This method scales more graceful to higher dimensional data and can thus work on a compression level which provides more faithful and detailed reconstructions than previous work and can be applied to high-resolution synthesis of megapixel images.
2- They achieve competitive performance on multiple tasks (image synthesis, inpainting, super-resolution) while significantly lowering computational costs.
3- This approach does not require a delicate weighting of reconstruction and generative abilities and requires very little regularization of the latent space.
4-They design a general-purpose conditioning mechanism based on cross-attention and use it to train class-conditional, text-to-image and layout-to-image models.
5-An advantage of this approach is that we need to train the universal auto-encoding stage only once and can therefore reuse it for multiple DM trainings.
Results:
1-This slide analyzes the behavior of our LDMs with different downsampling factors f ∈ {1, 2, 4, 8, 16, 32} (abbreviated as LDM-f, where LDM-1 corresponds to pixel-based DMs). We can see that, small down-sampling factors for LDM-{1,2} result in slow training progress, they attribute this to leaving most of perceptual compression to the diffusion model, whereas overly large values of f cause stagnating fidelity after few training steps, and they attribute this to too strong first stage compression resulting in information loss and thus limiting the achievable quality. LDM-{4-16} make a good balance between efficiency and perceptually faithful results. In the second figure, they compare models trained on CelebAHQ and ImageNet in terms sampling speed for different numbers of denoising steps and plot it against FID-scores. LDM-{4-8} outperform models with unsuitable ratios of perceptual and conceptual compression.
2-They train models of 256 squared images on 4 image datasets and evaluate results using FID and Precision-and-Recall. This Table summarizes their results. This model outperforms prior diffusion based approaches in most cases.

In my opinion the main strength of the paper is the idea of applying DM in a lower dimensional space or latent space using auto-encoding which is perceptually equivalent to the image space., thus we can use the power of DMs with an acceptable computational resource and time. The latent space is more suitable for generative models, as we can focus on the important, semantic bits of the data and train in a lower dimensional, computationally much more efficient space.
–> Link to the Paper <–