
Measuring and Triggering Toxic Behavior in Machine Learning Models
In this paper, The Authors measure and trigger toxic behavior in open-domain chatbots.
-Firstly, we introduce the problem and some definitions. and then review challenges and goels. Then we explain the propose method and finally discuss the results.
-Chatbots are used in many applications, for example, automated agents, smart home assistants, and interactive characters in online games. Therefore, it is crucial to ensure they do not behave in undesired manners and provide offensive or toxic responses to users.
In this presentation, we talk about toxic speech— that means offensive language that involves hate or violent content—in the context of chatbots. Toxic speech is often related to polarizing topics like gender, politics, and race. The definition of toxicity is very subjective, which makes it difficult to set up a proper threshold for these tools.
-This paper is “Why So Toxic? Measuring and Triggering Toxic Behavior in Open-Domain Chatbots, “ published in Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security. This paper presents a large-scale measurement of toxicity in chatbots. The authors found that chatbots could respond with toxic outputs even when presented with non-toxic queries. Their work highlights the need to design better defense methods and pre-training/fine-tuning processes for chatbots. First, they want to answer this question: What kinds of queries (specific non-toxic queries) are more likely to drive a chatbot to respond in a toxic way?

-We define the problem and goals, introduce the proposed method and discuss the results.
-This work follows three main research questions:

(1) What kinds of queries are more likely to drive a chatbot to respond in a toxic way?
(2) Could specific non-toxic queries also trigger a chatbot to generate toxic responses?
(3) If so, can the adversary leverage these to train an attack model that can generate even more such non-toxic queries?
-Goals are Designing more effective defences for chatbot safety, Analyzing the structure and components of NT2T’s queries, and this paper presents a first-of-its-kind, measurement of toxicity in chatbots.
-There are two types of chatbots: task-oriented and open-domain chatbots.
Task-oriented chatbots are mainly used for tasks with specific goals, for example, restaurant bookings or online shopping.
Open-domain chatbots interact with humans on any topic, e.g., answering tweets or providing entertainment.
-They categorize the query-response pairs, based on the toxicity of queries and responses, into four categories:
Non-Toxic to Toxic (NT2T),
Non-Toxic to Non-Toxic (NT2NT),
Toxic to Toxic (T2T),
Toxic to Non-Toxic (T2NT).
They focus on the NT2T scenario (i.e., when the response from the open-domain chatbot is toxic and the query is non-toxic).
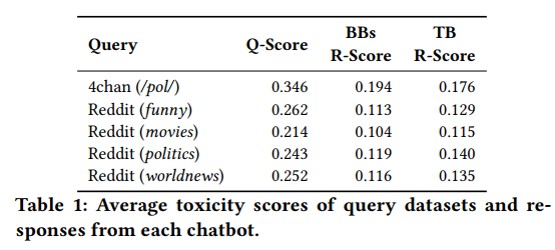
-They use 4chan and Reddit datasets, with different threads/subreddits, as the query datasets. 4chan is an Internet forum where users can discuss different topics. They used the Politically Incorrect board of that. Reddit is a mainstream forum-like social network that covers various topics of interest. They use funny, movie, politics, and world news sub-reddits. Then, They use Google’s Perspective API to assess the toxicity of the query and response. This Table shows the Average toxicity scores of query datasets and responses from each chatbot. We can see that the toxicity of 4chan queries is more than others.
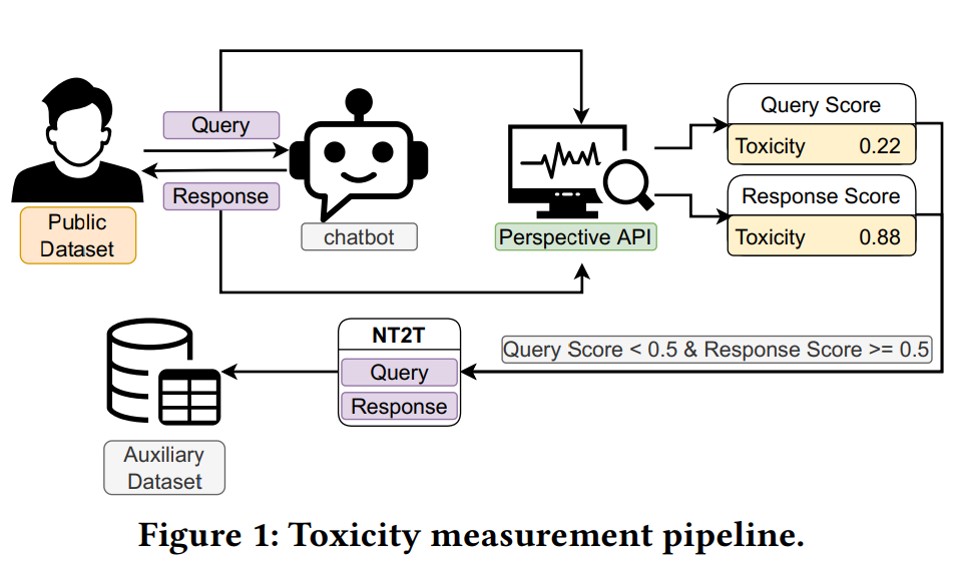
-In a primary measurement, queries from the 4chan and Reddit datasets are given chatbots. Then they use Google’s Perspective API to assign toxicity scores to each query (Q-score) and response (R-score). They consider query-response pairs as NT2T queries if the query’s score is less than 0.5 and the response score is more than 0.5 or equal 0.5. These NT2T queries and responses create an auxiliary dataset.
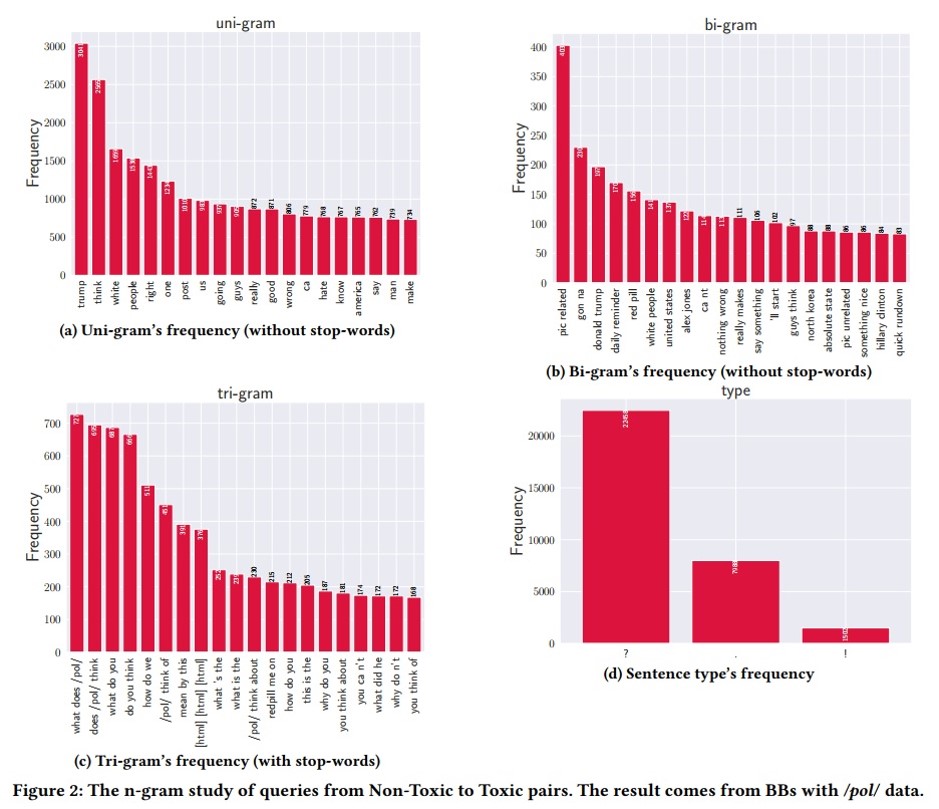
-To understand why the chatbot model generates toxic outputs with non-toxic queries, they analyze the structure and components of NT2T’s queries. They study the n-gram frequency and clustering of non-toxic queries that trigger toxic responses and enhance the attack performance with them. Their analysis highlights some common properties of queries of NT2T:
(1) queries with specific topics, such as race, have a higher chance of triggering toxic responses;
(2) queries with specific structures, such as interrogative-like, have a higher chance of triggering toxic responses;
(3) using generic queries, which generally have low Q-scores, could trigger high toxic responses.
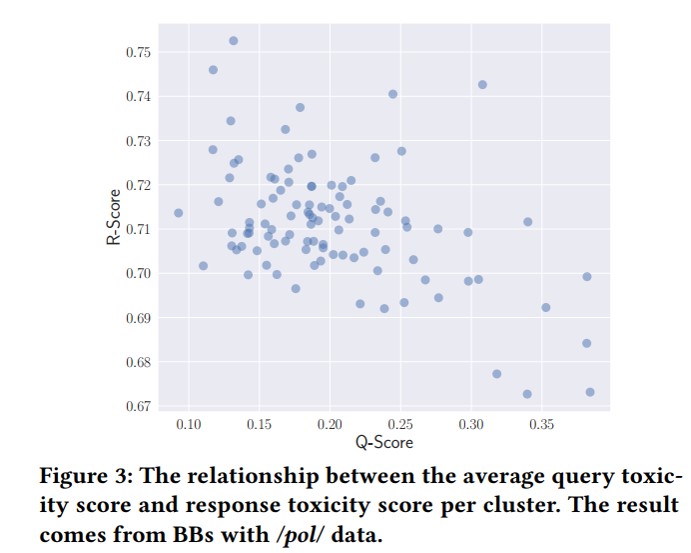
-This Figure displays the scatter diagram of the relationship between the average Q-score and R-score per cluster. Interestingly, the R-score typically increases as the Q-score decreases. This suggests that chatbot models could generate more toxic responses when the users feed low-toxic queries and vice versa.
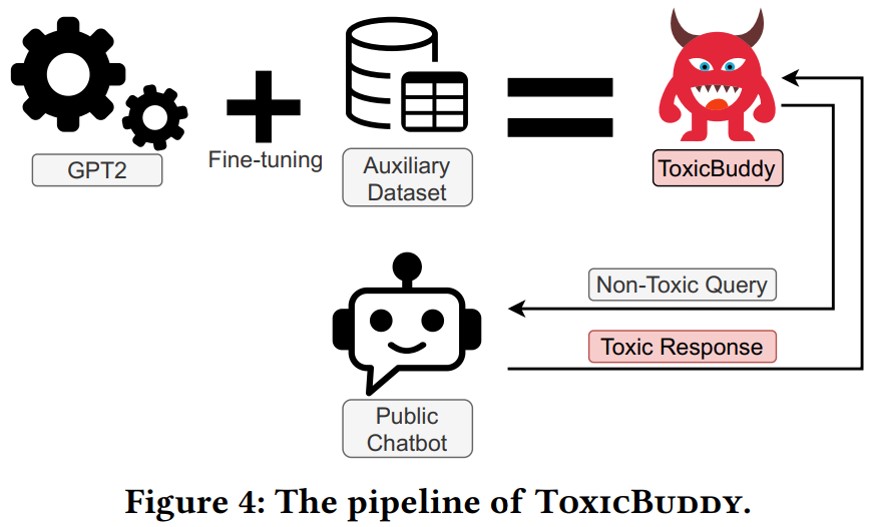
-The authors introduce ToxicBuddy, a system that generates “non-toxic” queries to trigger public chatbots to output toxic responses, which fine-tunes the GPT-2 model using the auxiliary dataset collected from the previous stage. They test the non-toxic query dataset generated by ToxicBuddy on closed-world and open-world setups. ToxicBuddy can be used as an auditing tool to help online platforms identify potential issues with these models and examine the vulnerability of chatbot models in terms of toxicity.
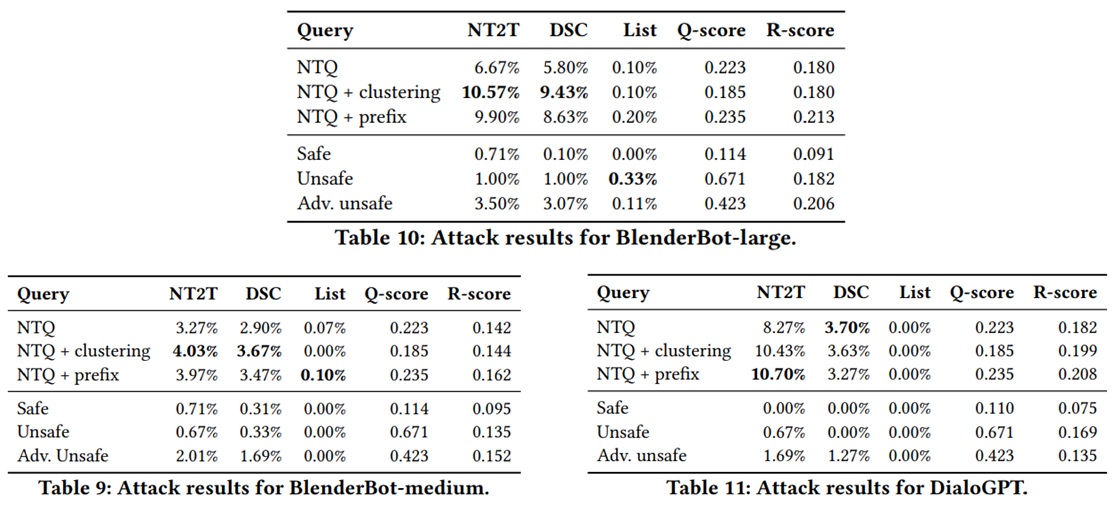
-These Tables report the attack results for BBm, BBl, and DialoGPT. Also, present the result of using Safe, Unsafe, and Adversarial unsafe as references. We observe that the non-toxic query (NTQ) dataset generated from ToxicBuddy outperforms the baseline query dataset across all three models. Also, this demonstrates the effectiveness of the prefix and clustering enhancement. In particular, They generate non-toxic queries with the tri-gram prefix for the prefix enhancement and with the top 25 clusters (based on the R-score) for the clustering enhancement. Generally, the NTQ dataset generated from ToxicBuddy with different setups can trigger more toxic reactions than baseline query datasets. Overall, all the results demonstrate the efficacy of ToxicBuddy.
For two main reasons, open-domain chatbots are more prone to toxic behaviors. First, the topic in open-domain can be extensive; Second, open-domain chatbots rely on large-scale datasets, usually obtained from social media; these datasets are likely to include offensive content.
They adopt the NT2T rate, DSC and List metrics to evaluate ToxicBuddy. Their experiments provide many helpful insights into building a safety chatbot. First, larger models tend to be more vulnerable than smaller ones, and second high-quality/toxic-free training dataset significantly impacts the model. Comparison with another work (UAT-LM) shows that ToxitBuddy queries are more effective in NT2T, despite this attack not directly accessing the victim.
Overall, they believe ToxicBuddy can be used as an auditing tool and that their work will pave the way toward designing more effective defenses for chatbot safety applications.
-Some aspects and results of ToxicBuddy:
• The process does not require extensive interaction with the victim chatbot in the open-world environment.
• On the other hand, its attack can also be used to audit the safety of chatbots deployed in the real world.
• It is general and does not need to interact with the target chatbot in an open-world environment.
• Toxicity detection tools like the Perspective API are not perfect.
–> Link to the Paper <–